





单细胞数据数据量很大,加重了分析的负担,但只要掌握好的方法和工具,就可以无往而不利。今年要说的这个如题,是因为在区分亚类的时候,提取了大类型并调整分辨率重新聚类计算的亚类。针对这种情况,该如何实现呢?
问题分析
其实该问题可以简化为把每个亚类的分类信息提取出来并给大类进行赋值,然后使用Seurat内置的DotPlot功能进行作图,样式可以微调。
解决方法
有了方案,解决起来就简单了!
首先,markers基因先输入,然后把大类读入内存并操作一下
library(RColorBrewer) |
然后,把需要的三个亚类读入内容并处理亚类和大类之间的映射关系
for (i in c(1,3,4)){ |
把新的到的分组信息传入到大类中并设置好因子顺序,将其定义为Idents
endo$new_group<-need |
最后作图微调并保存
DefaultAssay(endo)<-"RNA" |
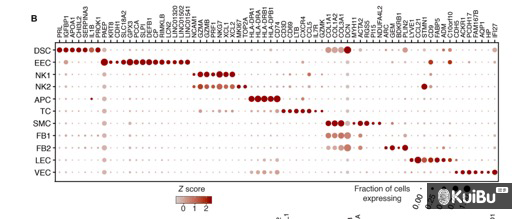
图形如下:

另外的图?
针对以上的方法,我们可以把每个亚类的关系都映射到大类的umap图上,以尽量展示所有的关系
library(RColorBrewer) |

