1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
import streamlit as st
import pandas as pd
import os
st.set_page_config(
page_title="Excel toolkits",
layout="wide"
)
@st.cache_data
def read_data(upload_file):
df = pd.read_excel(upload_file)
df.columns = ["n"+str(i+1) for i in range(df.shape[1])]
df = df.fillna('')
return df
def read_data2(upload_file):
duiying = pd.read_excel(upload_file)
duiying.columns = ["sampleName","trueName"]
return duiying
def makenames(df,col):
s='_'+df.groupby(col).cumcount().add(1).astype(str)
df.loc[:,col]+=s.mask(s=="_1","")
return df
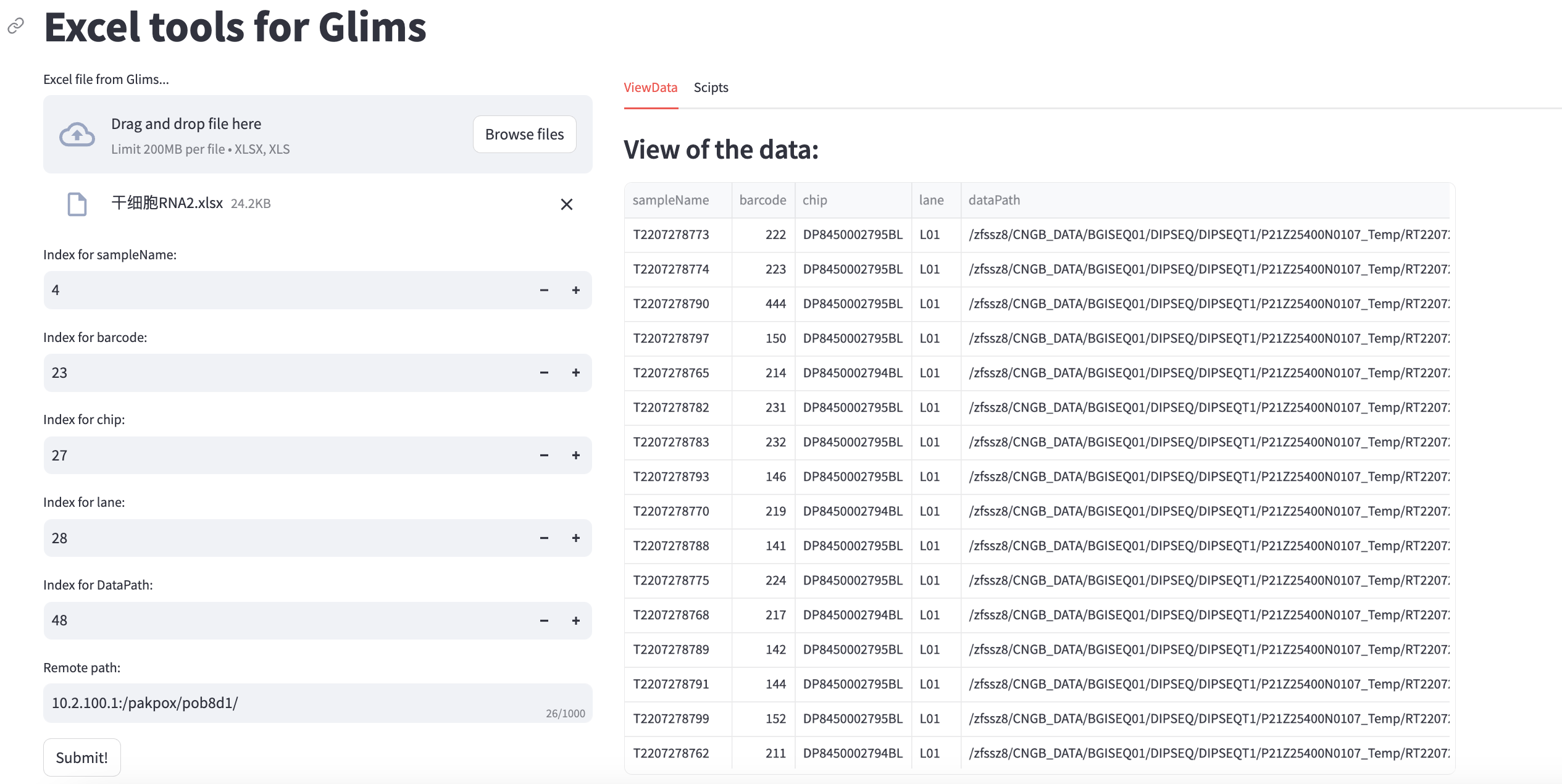
st.title("Excel tools for Glims")
col1, col2 = st.columns([0.35,0.65],gap="medium")
with col1:
upload_data = st.file_uploader(label="Excel file from Glims...",
type=['xlsx','xls'])
SM_index = st.number_input(label="Index for sampleName:",
min_value=1,
max_value=62,
value=4)
BC_index = st.number_input(label="Index for barcode:",
min_value=1,
max_value=62,
value=23)
CP_index = st.number_input(label="Index for chip:",
min_value=1,
max_value=62,
value=27)
LN_index = st.number_input(label="Index for lane:",
min_value=1,
max_value=62,
value=28)
Path_index = st.number_input(label="Index for DataPath:",
min_value=1,
max_value=62,
value=48)
Remote_path = st.text_input(label="Remote path:",
value="10.2.100.1:/pakpox/pob8d1/",
max_chars=1000)
isSubmit = st.button("Submit!")
st.divider()
placeholder = st.empty()
upload_data2 = st.file_uploader(label="Input Barcode with sampleName:",
type=['xlsx','xls'])
with col2:
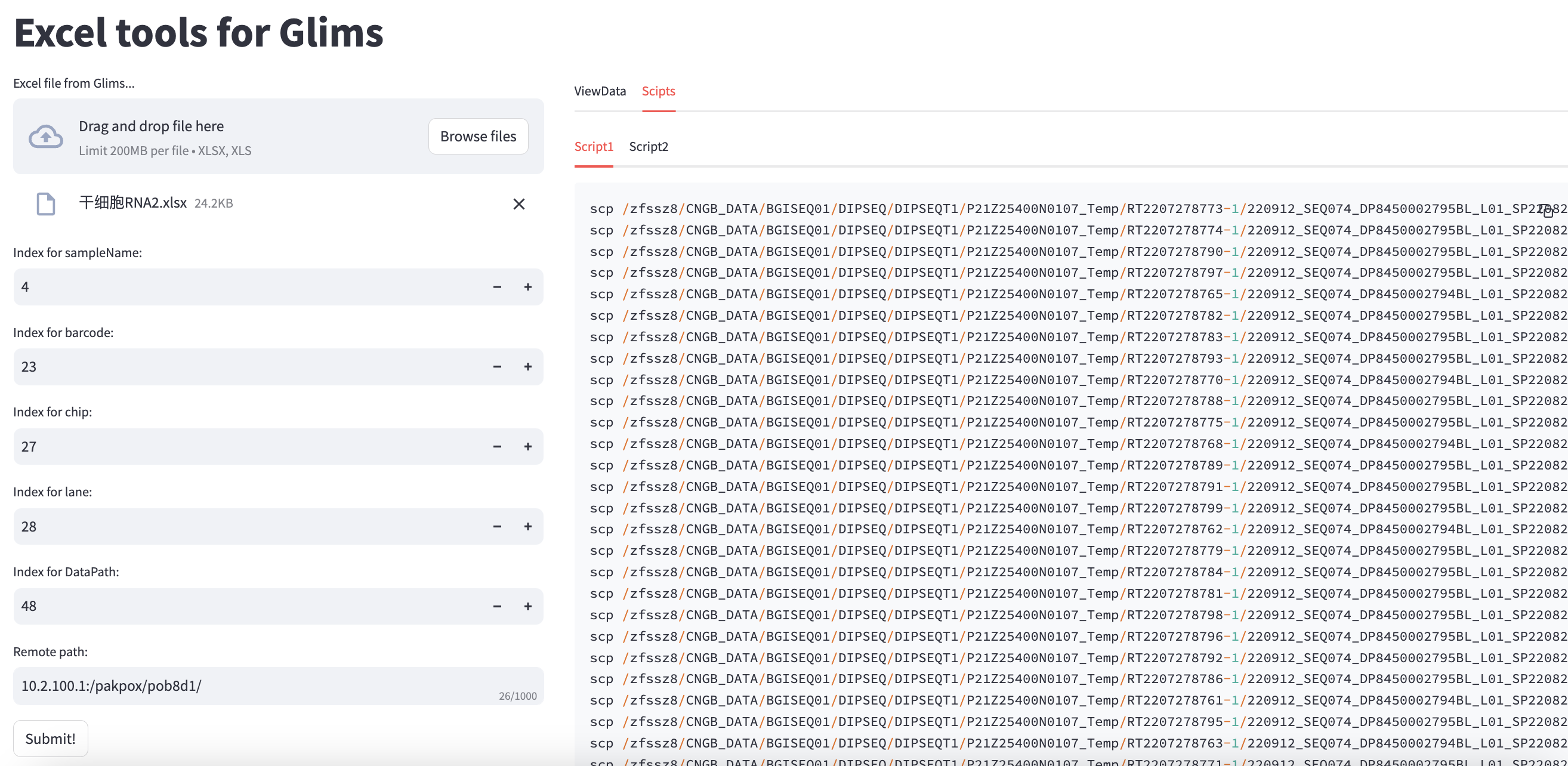
tab1, tab2 = st.tabs(["ViewData", "Scipts"])
tab21, tab22 = tab2.tabs(["Script1", "Script2"])
upcontent = tab1.container()
upcontent.subheader("View of the data:")
if upload_data is not None:
dataframes = read_data(upload_data)
df = dataframes.iloc[:,[SM_index-1,BC_index-1,CP_index-1,LN_index-1,Path_index-1]]
df.columns = ["sampleName", "barcode", "chip", "lane", "dataPath"]
if df.sampleName.duplicated().any():
tab1.warning("Duplicated sampleName found, fixing...")
df = makenames(df,"sampleName")
if upload_data2 is not None:
placeholder.info("After upload data, please click the button again!")
df2 = read_data2(upload_data2)
df = df.merge(df2,how="left",on="sampleName")
df = df.drop(columns=["sampleName"])
df = df.rename(columns={"trueName":"sampleName"})
df = df[~df["sampleName"].isna()]
if isSubmit:
upcontent.dataframe(df,hide_index=True,height=600)
df = df.assign(filename1=df.apply(lambda row : "_".join([row['chip'],row['lane'],str(row['barcode']),"1.fq.gz"]),axis=1))
df = df.assign(filename2=df.apply(lambda row : "_".join([row['chip'],row['lane'],str(row['barcode']),"2.fq.gz"]),axis=1))
cmd1 = df.apply(lambda row: "scp " + os.path.join(row['dataPath'],row['filename1']) + " " + os.path.join(Remote_path,row['sampleName'] + "_R1.fastq.gz"),axis=1).tolist()
cmd2 = df.apply(lambda row: "scp " + os.path.join(row['dataPath'],row['filename2']) + " " + os.path.join(Remote_path,row['sampleName'] + "_R2.fastq.gz"),axis=1).tolist()
tab21.code("\n".join(cmd1))
tab22.code("\n".join(cmd2))
|